The Fragmentation of Enterprise Workflow: From Brittle Scripts to Agentic Reasoning
25 February 2026
For the better part of a decade enterprise workflow, such as data engineering, operated under the assumption that if we centralized data into a warehouse and built a dashboard then value would automatically follow. This was the golden era of the “Modern Data Stack” where visualization was seen as the ultimate deliverable [1]. However at Terralogiq managing massive datasets for some of Indonesia’s largest retail enterprises and government institutions taught us the hard way that this assumption is dead.

Our business clients do not have time to navigate complex menus in Looker and our field agents in rural areas lack the connectivity to sift through heavy mobile dashboards. They need answers pushed to them formatted for immediate action. We realized that the dashboard paradigm often fails to bridge the “last mile” of analytics where data needs to trigger a physical response in the real world.
Key Takeaways:
- Dashboards are not enough: Centralized data visualization fails to serve field agents and busy executives who need push-based actionable insights.
- Scripts are brittle: Traditional linear automation cannot handle the variability of real-world enterprise data leading to high maintenance costs.
- Agents provide reasoning: shifting to an Agentic Architecture allows systems to observe, plan, and execute tasks dynamically using LLMs as a reasoning engine.
The Hidden Cost of Fragmented Operations in Enterprise Workflow
The problem goes far beyond ignored dashboards. We found that the actual day-to-day operations of these large organizations were still drowning in fragmented and manual processes. We saw government agencies relying on armies of staff to manually verify documents because standard OCR models were not reliable enough for high-stakes validation. We saw retail enterprises paralyzed by brittle Python scripts running on cron jobs trying to glue together disparate APIs that would break whenever a schema changed [2].
In the past, we tried deploying traditional Machine Learning models but they created isolated silos of intelligence. These models were good at one narrow task but incapable of connecting the dots across a complex workflow. Even early attempts at using Large Language Models (LLMs) failed in these high-stakes environments. For example, a government report cannot tolerate a 5% hallucination rate in its data regardless of how fluent the summary sounds.
Due to the prominence of these problems, we were drowning in maintenance tickets trying to manually govern thousands of brittle pipelines, verify thousands of images from the field, and police erratic API outputs. We realized we didn’t just need better automation scripts or stronger individual models. We needed a connective layer that could reason across them all. This realization drove our critical pivot toward advanced agentic platforms like Google’s Agent Development Kit (ADK) and breakthrough visual tools like Nano Banana Pro.
Moving from Scripts to Agents
The shift to an Agentic Architecture was driven by the need for a system that could act like a human analyst. We utilized platforms which empowered agentic functionalities such as LangChain, Pydantic, or the newly established agent development platform Google’s Gen AI Agent Development Kit (ADK) to build an insight agentic workflow [3]. Unlike a linear script this agent uses Gemini as a reasoning engine. It does not just execute a task, but also observes the incoming data and decides which tools are necessary to process it. Then, as the final step, it executes a plan.
Deployment of the new system was done on a serverless event-driven stack using Google Cloud Run for the orchestration and Firestore for state management. This allows the system to maintain “memory” of a transaction without the overhead of managing persistent servers.
Read Also: Implementasi AI dalam Bisnis: Transformasi dan Manfaatnya
The Visual Layer: Solving Hallucinations
The critical component, however, was how we handled the visual layer. Standard diffusion models are notorious for hallucinating the text turning a 90% metric into a gibberish glyph. There are several ways to solve this but we integrated a specialized tool capability called Nano Banana Pro on Vertex AI. This model utilizes spatial attention mechanisms allowing the agent to map specific tokens to specific pixel coordinates [4].
The new mechanism leveraged the agent to be able to read a database row and write it onto an image with near-perfect accuracy, solving the reliability gap that usually prevents GenAI from being used in enterprise reporting. By grounding the generative process in specific pixel coordinates we ensure that the output is faithful to the input data.
Table 1: Comparison of Automation Approaches
| Feature | Traditional Scripting | Agentic Workflow (ADK) |
| Logic Flow | Linear (If-This-Then-That) | Dynamic (Observation-Reasoning-Action) |
| Resilience | Brittle, breaks on schema change | High, agent adapts to input variations |
| Visual Processing | Basic OCR or pixel matching | Semantic understanding with spatial attention |
| Maintenance | High, requires manual code updates | Low, logic is handled by the reasoning engine |
Read Also: Gemini Enterprise Kegunaan dan Manfaatnya dalam Strategi Implementasi AI di 2026
Exploring the Frontiers of Visual Verification
Now that we have established the core visual layer we are currently exploring use cases that go far beyond simple executive reporting because we want to solve the messy real-world problems of the Indonesian market. For instance verifying shelf displays in thousands of Warungs in the general trade sector is a logistical nightmare. We are developing tool definitions that allow the agent to analyze a shelf photo against a planogram. If the compliance score is low the agent can use semantic inpainting to synthetically stock the missing products. The goal is to send a corrected visual back to the field rep which shows them exactly what the shelf should look like.
Similarly, we are prototyping document handling workflows for the fintech and insurance sectors. The vision is for the agent to assess the legibility of a KTP or invoice immediately upon upload. If the image were blurry, the agent would not just reject it. It would also generate a visual overlay highlighting the specific error to the user. Once the image passed, the agent would handle the extraction of text into structured JSON. We believe this will drastically reduce the manual data entry load and allow human teams to focus on complex validation rather than data entry.
The Blueprint: Designing the Tools
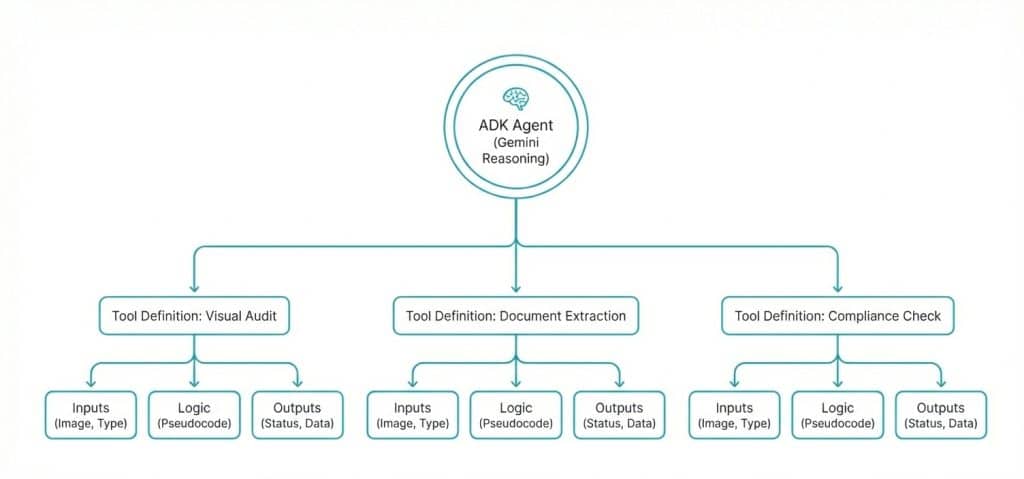
The power of the ADK lies in how we define these tools since we are not writing imperative code that tells the system exactly what to do step-by-step. Instead we are providing the agent with a set of capabilities and training it to determine the best course of action [5].
Below is a pseudocode representation of how we are currently structuring the Visual Audit tool. You can see how we are attempting to merge the reasoning capabilities of Gemini with the execution power of the Nano Banana model.
DEFINE TOOL: Audit_And_Extract_Visual_Evidence
INPUTS: image_uri, audit_type (SHELF, DOCUMENT, PROPERTY)
BEGIN
// Step 1: The Brain
// Gemini analyzes the image to determine quality and context
SET analysis = CALL Gemini.Analyze(image_uri, mode=audit_type)
// Step 2: Quality Check Logic
// We are designing the agent to visualize the error, not just flag it.
IF analysis.quality_score < 7 THEN:
SET annotated_image = CALL VertexAI.EditImage(
source = image_uri,
target = defect_area,
prompt = Highlight defect with high-contrast red overlay
)
RETURN { status: REJECTED, reason: analysis.reason, guide_image: annotated_image }
// Step 3: Branching Logic based on Audit Type
IF audit_type IS DOCUMENT THEN:
// For documents, the agent attempts structured text extraction
SET extracted_data = CALL Gemini.ExtractText(image_uri)
RETURN { status: APPROVED, data: extracted_data, rank: analysis.quality_score }
ELSE:
// For physical assets, we return the ranking and insights
RETURN { status: APPROVED, rank: analysis.quality_score, insights: analysis.summary }
END
Engineering with Empathy

As we develop these powerful tools, we are acutely aware of the ethical implications within the Indonesian context where there is a valid anxiety regarding AI displacing jobs. However, our design philosophy is centered on a human-in-the-loop architecture because we are building this system to be a force multiplier rather than a replacement [6]. The goal is to automate the drudgery such as pixel pushing, manual tagging, and data entry so that our designers and field agents can focus on high-value tasks.
Furthermore, we are building this entire stack within the Jakarta region to ensure strict compliance with the Personal Data Protection Law or UU PDP [7]. We believe that the future of AI in Indonesia depends on building systems that are not only powerful but also trustworthy and respectful of data sovereignty.
Stay connected with Terralogiq to get the latest information! Follow our Instagram and LinkedIn accounts for the latest updates and do not hesitate to contact us via email at halo@terralogiq.com. We are ready to help you!
Bibliography
- Eckerson, W. W. (2010). Performance dashboards: measuring, monitoring, and managing your business. John Wiley & Sons.
- Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., … & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in neural information processing systems, 28.
- Google Cloud. (2024). Build agents with the Gen AI Agent Development Kit. Google Developers. Retrieved from https://developers.google.com/
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Chase, H. (2023). LangChain Documentation. Retrieved from https://python.langchain.com/
- Daugherty, P. R., & Wilson, H. J. (2018). Human+ machine: Reimagining work in the age of AI. Harvard Business Press.
- Government of Indonesia. (2022). Law Number 27 of 2022 on Personal Data Protection (UU PDP).
Leave a Reply